Quelle est la surcharge engendrée par une recherche texte ? - Conseil sur la base de données MySQL
Conseil sur la base de données MySQL
Quelle est la surcharge engendrée par une recherche texte ?
Les recherches dans une base de données constituent un des points les plus sensibles dans la gestion de la charge d'un serveur web.
Ainsi, pour la recherche d'un enregistrement, il est recommandé d'effectuer une recherche grâce à son identifiant numérique.
Cependant, certains sites (notamment Wikipédia et Youtube) semblent se passer des identifiant dans leurs liens.
http://fr.wikipedia.org/wiki/Wikipédia
Une analyse des liens de Wikipédia permet de voir que la recherche du nom d'un article se fait sur la chaîne de caractères. Il n'y a aucune trace d'un identifiant numérique. La recherche se fait donc obligatoirement sur une chaîne de caractères.
http://www.youtube.com/watch?v=Y7dpJ0oseIA
De même, les URLs utilisés par Youtube incluent en paramètre une chaîne de caractères alphanumériques sensibles à la casse. Là aussi, la recherche passe donc forcément par une recherche sur une chaîne de caractères.
Le traitement de ces recherches entraîne une augmentation de l'utilisation des ressources d'une machine.
Ce test tente d'estimer le temps supplémentaire nécessaire pour traiter ces requêtes. Les tests sont effectués sur une table MySQL nommée TEST contenant 2 champs : TEST_id et TEST_data. Le champ TEST_id était soit de tpye INTEGER avec un paramètre AUTO_INCREMENT ou un VARCHAR(50). Le champ TEST_data était VARCHAR(50).
Pour niveler les résultats et éliminer les pics d'activités externes, chaque configuration a été testée 10 000 fois.
Les mesures de temps sont effectuées selon l'ordre suivant :
création du tableau des identifiants recherchés;
mesure du temps 1;
connexion à la base de données;
requête;
traitement du résultat et affichage;
mesure du temps 2;
Ces résultats sont représentés par les barres rouges. Pour les mesures de durée de la requête uniquement (les barres vertes sur les graphiques), la "mesure du temps 1" intervient juste après la connexion à la base de données.
La table TEST a été remplie avec 1 000 000 d'enregistrements. Le champ TEST_id était soit alimenté par un entier ou par une chaîne de caractères de type [a-z0-9] de 8 caractères de longueurs en moyenne. Chaque enregistrement était unique.
On peut noter que le temps de remplissage (environ 300 secondes soit 5 minutes) de la table est resté à peu près identique quelque soit les types d'insertions (numériques ou alphanumériques). Les index sur les champs ont été ajoutées ensuite.
Les différences entre les configurations testées portent sur le champ TEST_id :
La durée de chaque opération a été mesurée avec la fonction microtime(true) au début et à la fin du processus.
Pour chaque test, 2 mesures ont été produites : sans et avec la prise en compte de la connexion à la base de données.
Avant chaque recherche, un tableau des recherches est constitué pour minimiser l'influence du temps de création d'un identifiant aléatoire.
Les recherches sur le champ TEST_id sont effectuées de 2 manières selon son type :
Pour un champ de type INTEGER :
"SELECT TEST_data FROM TEST WHERE TEST_id=".$i
Pour un champ de type VARCHAR(50), il existe 2 possibilités suivant l'indexation :
Champ VARCHAR(50) non indexé ou avec un index normal :
"SELECT TEST_data FROM TEST WHERE TEST_id='".$i."'"
Champ VARCHAR(50) indexé en fulltext :
"SELECT TEST_data FROM TEST WHERE MATCH(TEST_id) AGAINST ('".$i."')"
Le premier test consiste en une recherche d'un enregistrement aléatoire sur le champ TEST_id. Le résultat est l'enregistrement du champ TEST_data.
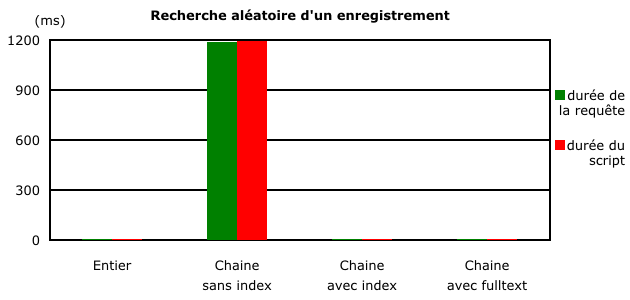
La différence est flagrante pour le champ non indexé. Pour la clarté de l'affichage, le graphique suivant a volontairement été limité à un intervalle compris entre 0 et 2 ms. La recherche sur un champ texte sans index prend plus de 1 seconde et dépasse largement le champ de représentation.
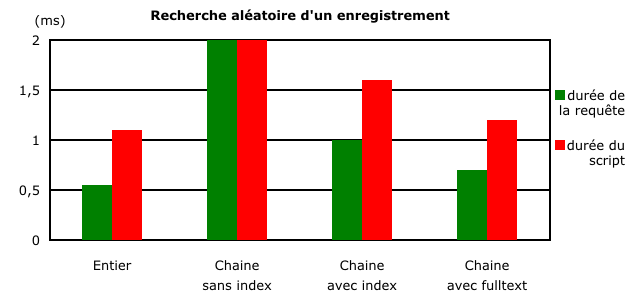
L'avantage est clairement pour une recherche sur un champ de type entier. Cependant on constate que le type d'index influe sur la durée de la recherche. Utiliser un index fulltext entraîne un gain de temps d'environ 30 % par rapport à une indexation classique. Au final, la recherche sur une chaîne de caractères nécessite, dans le meilleur des cas, 27 % de temps supplémentaire qu'une recherche sur un entier.
L'influence du temps nécessaire à la connexion à la base apparait aussi, il est dans ce cas de l'ordre de 0,5 ms.
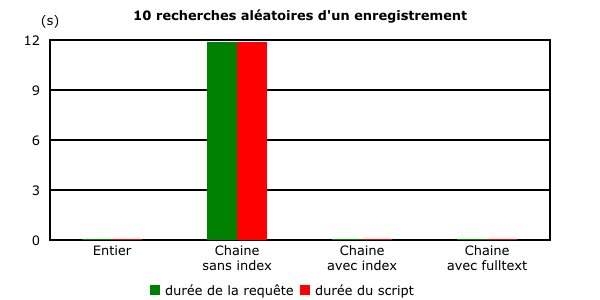
La différence apparait aussi nettement. Pour la clarté de l'affichage, le graphique suivant a volontairement été limité à un intervalle compris entre 0 et 10 ms. La recherche sur un champ texte sans index prend plus de 11 secondes et dépasse largement le champ de représentation.
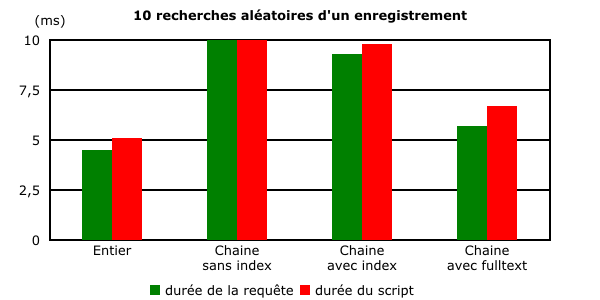
Le temps de connexion prend ici moins d'importance. Les conclusions du test précédent sont toujours valables. Une recherche sur un champ indexé de type chaîne de caractères prend 2 fois plus de temps qu'une recherche sur un champ de type entier. La recherche en plein texte nécessite 30 % de temps supplémentaire.
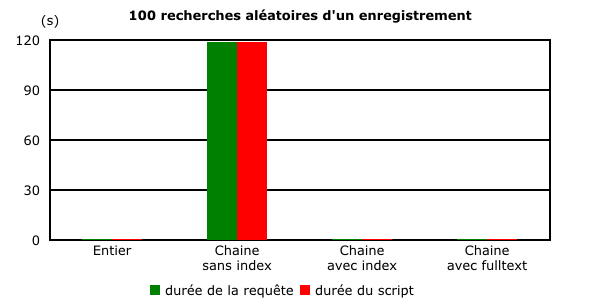
Les précédentes différences restent d'actualité. Pour la clarté de l'affichage, le graphique suivant a volontairement été limité à un intervalle compris entre 0 et 100 ms. La recherche sur un champ texte sans index prend plus de 118 secondes et dépasse largement le champ de représentation.
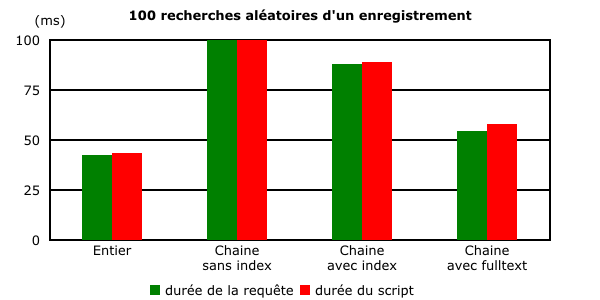
Les conclusions des 2 tests précédents sont toujours valables. Une recherche sur un champ indexé de type chaîne de caractères prend 2 fois plus de temps qu'une recherche sur un champ de type entier. La recherche en texte intégral nécessite 28 % de temps supplémentaire.
Logiquement, la recherche sur une chaîne de caractères nécessite plus de temps de traitement. Cependant, les différentes manières d'indexation d'un champ de type chaîne de caractères permettent de limiter cette augmentation. L'index classique nécessite en moyenne 2 fois plus de temps qu'une recherche sur un entier.
La méthode la plus efficace passe par l'utilisation d'une recherche de texte libre (fulltext) qui entraine quand même un traitement 30 % plus long. L'inconvénient de cette méthode réside dans l'espace disque supplémentaire occupé par l'indexation.
Ainsi, pour la recherche d'un enregistrement, il est recommandé d'effectuer une recherche grâce à son identifiant numérique.
Cependant, certains sites (notamment Wikipédia et Youtube) semblent se passer des identifiant dans leurs liens.
http://fr.wikipedia.org/wiki/Wikipédia
Une analyse des liens de Wikipédia permet de voir que la recherche du nom d'un article se fait sur la chaîne de caractères. Il n'y a aucune trace d'un identifiant numérique. La recherche se fait donc obligatoirement sur une chaîne de caractères.
http://www.youtube.com/watch?v=Y7dpJ0oseIA
De même, les URLs utilisés par Youtube incluent en paramètre une chaîne de caractères alphanumériques sensibles à la casse. Là aussi, la recherche passe donc forcément par une recherche sur une chaîne de caractères.
Le traitement de ces recherches entraîne une augmentation de l'utilisation des ressources d'une machine.
Protocole
Ce test tente d'estimer le temps supplémentaire nécessaire pour traiter ces requêtes. Les tests sont effectués sur une table MySQL nommée TEST contenant 2 champs : TEST_id et TEST_data. Le champ TEST_id était soit de tpye INTEGER avec un paramètre AUTO_INCREMENT ou un VARCHAR(50). Le champ TEST_data était VARCHAR(50).
Pour niveler les résultats et éliminer les pics d'activités externes, chaque configuration a été testée 10 000 fois.
Les mesures de temps sont effectuées selon l'ordre suivant :
création du tableau des identifiants recherchés;
mesure du temps 1;
connexion à la base de données;
requête;
traitement du résultat et affichage;
mesure du temps 2;
Ces résultats sont représentés par les barres rouges. Pour les mesures de durée de la requête uniquement (les barres vertes sur les graphiques), la "mesure du temps 1" intervient juste après la connexion à la base de données.
La table TEST a été remplie avec 1 000 000 d'enregistrements. Le champ TEST_id était soit alimenté par un entier ou par une chaîne de caractères de type [a-z0-9] de 8 caractères de longueurs en moyenne. Chaque enregistrement était unique.
On peut noter que le temps de remplissage (environ 300 secondes soit 5 minutes) de la table est resté à peu près identique quelque soit les types d'insertions (numériques ou alphanumériques). Les index sur les champs ont été ajoutées ensuite.
Les différences entre les configurations testées portent sur le champ TEST_id :
| Nom du test | Type du champ | Type d'index | Poids | |
|---|---|---|---|---|
| Données | Index | |||
| Entier | INTEGER | Aucun | 26 Mo | 0 Mo |
| Chaîne sans index | VARCHAR(50) | Aucun | 30 Mo | 0 Mo |
| Chaîne avec index | VARCHAR(50) | Index | 30 Mo | 11 Mo |
| Chaîne avec fulltext | VARCHAR(50) | Fulltext | 30 Mo | 17 Mo |
La durée de chaque opération a été mesurée avec la fonction microtime(true) au début et à la fin du processus.
Pour chaque test, 2 mesures ont été produites : sans et avec la prise en compte de la connexion à la base de données.
Tests
Avant chaque recherche, un tableau des recherches est constitué pour minimiser l'influence du temps de création d'un identifiant aléatoire.
Les recherches sur le champ TEST_id sont effectuées de 2 manières selon son type :
Pour un champ de type INTEGER :
"SELECT TEST_data FROM TEST WHERE TEST_id=".$i
Pour un champ de type VARCHAR(50), il existe 2 possibilités suivant l'indexation :
Champ VARCHAR(50) non indexé ou avec un index normal :
"SELECT TEST_data FROM TEST WHERE TEST_id='".$i."'"
Champ VARCHAR(50) indexé en fulltext :
"SELECT TEST_data FROM TEST WHERE MATCH(TEST_id) AGAINST ('".$i."')"
1er test : recherche d'un enregistrement aléatoire
Le premier test consiste en une recherche d'un enregistrement aléatoire sur le champ TEST_id. Le résultat est l'enregistrement du champ TEST_data.
La différence est flagrante pour le champ non indexé. Pour la clarté de l'affichage, le graphique suivant a volontairement été limité à un intervalle compris entre 0 et 2 ms. La recherche sur un champ texte sans index prend plus de 1 seconde et dépasse largement le champ de représentation.
L'avantage est clairement pour une recherche sur un champ de type entier. Cependant on constate que le type d'index influe sur la durée de la recherche. Utiliser un index fulltext entraîne un gain de temps d'environ 30 % par rapport à une indexation classique. Au final, la recherche sur une chaîne de caractères nécessite, dans le meilleur des cas, 27 % de temps supplémentaire qu'une recherche sur un entier.
L'influence du temps nécessaire à la connexion à la base apparait aussi, il est dans ce cas de l'ordre de 0,5 ms.
2ème test : 10 recherches aléatoires d'un enregistrement
La différence apparait aussi nettement. Pour la clarté de l'affichage, le graphique suivant a volontairement été limité à un intervalle compris entre 0 et 10 ms. La recherche sur un champ texte sans index prend plus de 11 secondes et dépasse largement le champ de représentation.
Le temps de connexion prend ici moins d'importance. Les conclusions du test précédent sont toujours valables. Une recherche sur un champ indexé de type chaîne de caractères prend 2 fois plus de temps qu'une recherche sur un champ de type entier. La recherche en plein texte nécessite 30 % de temps supplémentaire.
3ème test : 100 recherches aléatoires d'un enregistrement
Les précédentes différences restent d'actualité. Pour la clarté de l'affichage, le graphique suivant a volontairement été limité à un intervalle compris entre 0 et 100 ms. La recherche sur un champ texte sans index prend plus de 118 secondes et dépasse largement le champ de représentation.
Les conclusions des 2 tests précédents sont toujours valables. Une recherche sur un champ indexé de type chaîne de caractères prend 2 fois plus de temps qu'une recherche sur un champ de type entier. La recherche en texte intégral nécessite 28 % de temps supplémentaire.
Conclusion
Logiquement, la recherche sur une chaîne de caractères nécessite plus de temps de traitement. Cependant, les différentes manières d'indexation d'un champ de type chaîne de caractères permettent de limiter cette augmentation. L'index classique nécessite en moyenne 2 fois plus de temps qu'une recherche sur un entier.
La méthode la plus efficace passe par l'utilisation d'une recherche de texte libre (fulltext) qui entraine quand même un traitement 30 % plus long. L'inconvénient de cette méthode réside dans l'espace disque supplémentaire occupé par l'indexation.
Les autres astuces du même thème :
Quelle est la surcharge engendrée par une recherche texte ?
Quelles sont les performances des différentes méthodes d'accès ?